Mes clusters musicaux
- Codage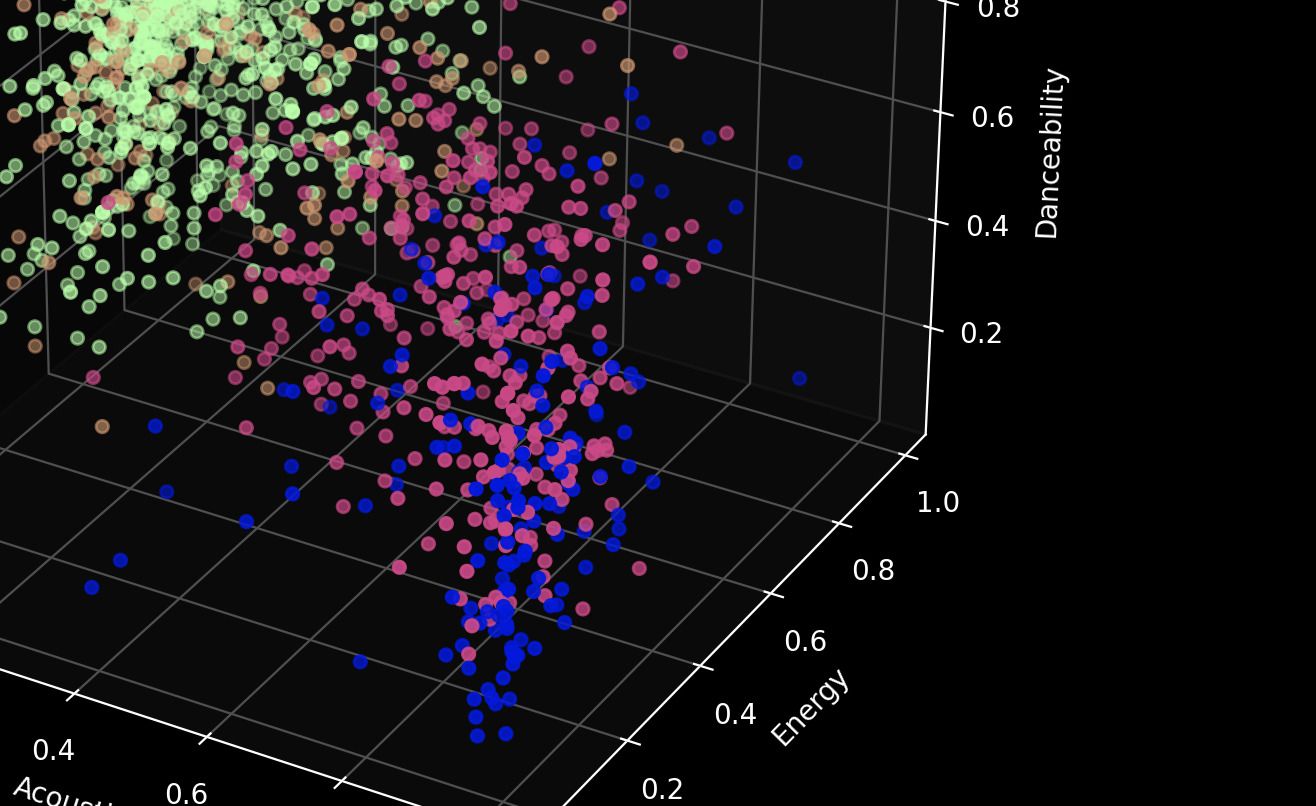
Pour la fac j'ai du étudier les méthodes de clustering. Pour faire court, il s'agit d'algorithmes qui permettent de classifier automatiquement des données. Je devais choisir un ensemble de données, j'ai choisi l'analyse musicale de mes morceaux préférés sur Spotify. Le résultat est intéressant. Je vais voir si ça m'apprend des choses sur moi-même.
Les données
Spotify, en grand prince, nous donne accès à des caractéristiques musicales pour chaque morceau. Et comme il nous donne aussi accès à la liste des morceaux enregistrés par utilisateur, on peut récupérer pour nos propres morceaux plein de caractéristiques musicales. Les détails sont présents sur cette page. Moi je me suis arrêté aux caractéristiques suivantes :
- acousticness : si le morceau est acoustique (ou électronique)
- danceability : si le morceau se danse ou pas
- intrumentalness : à quel point le morceau est instrumental ou chanté
- energy : à quel point le morceau est énergique
Pour chacune des ces caractéristiques, Spotify fournit une valeur comprise entre 0 et 1. Si on s'arrête à ces 4 marqueurs, on obtient pour chaque morceau un point détenant une coordonnée à 4 dimensions. C'est très important pour la suite car ça permettra à nos algorithmes de calculer les distances entre chaque point.
Les résultats
J'ai fait tourné plusieurs algorithmes (K-Means, Mean Shift, Affinity Propagation et Agglomerative Clustering) et le K-Means a été le plus pertinent pour une classification à quatre clusters. Si on met le résultat dans un espace à 3 dimensions, on bient les petites visualisations suivantes :
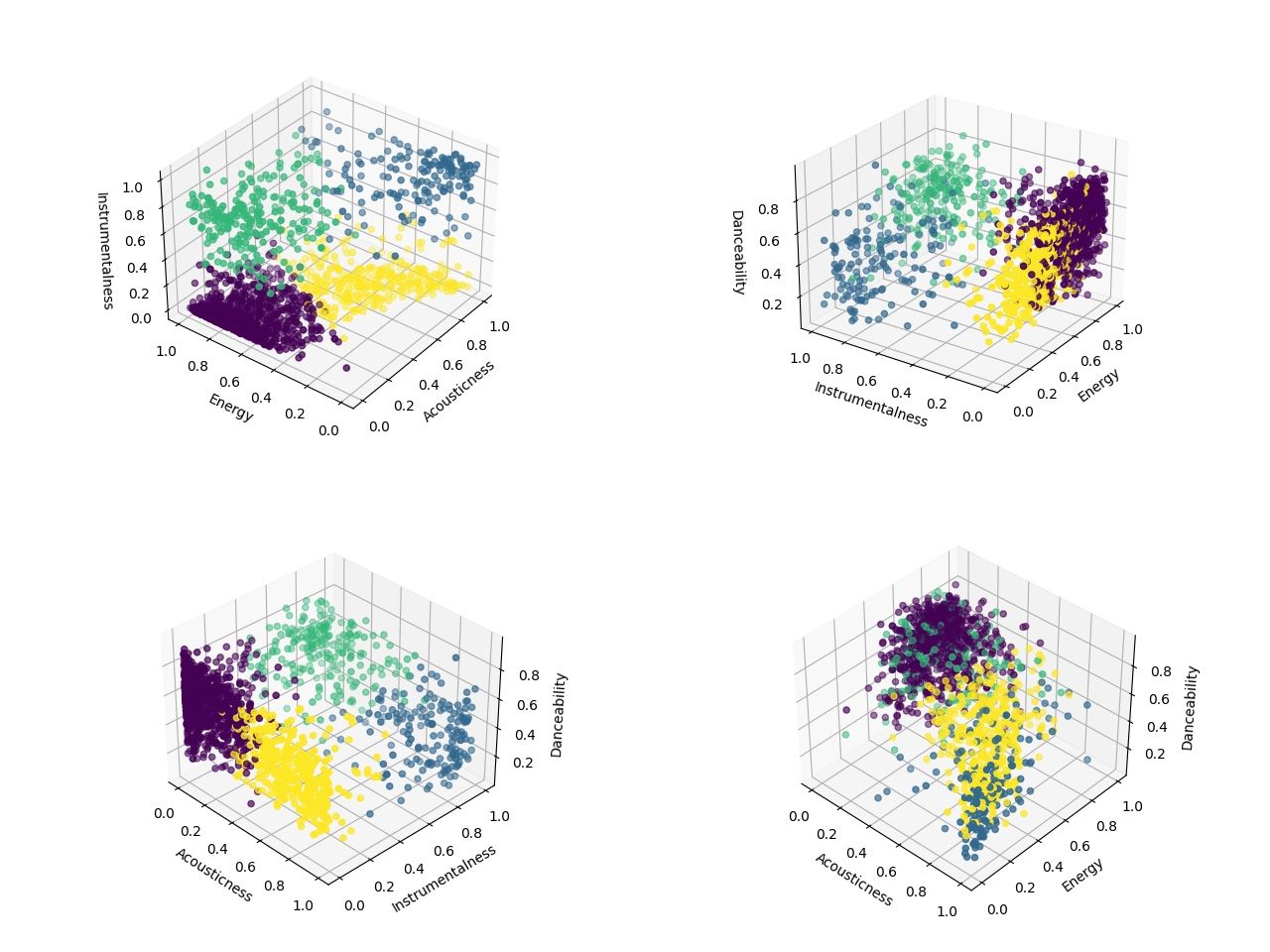
| Cluster | Taille |
|---|---|
| violet | 915 |
| jaune | 363 |
| vert | 225 |
| bleu | 165 |
Qu'est ce qu'on observe ?
Je n'ai eu aucune formation sur la lecture de clusters... Donc je vais y aller à l'analyse de comptoir. Déjà, on peut mettre de côté les clusters deux minutes et regarder les tendances générales que partagent mes morceaux ! La première tendance importante est que plus le morceau est acoustique, moins celui-ci est énergique et inversement. Cela ne me surprend pas car j'écoute beaucoup de folk pour me détendre et de la musique électro pour me filer la pêche.
On aperçoit aussi qu'une grosse partie de ma bibliothèque comprend des morceaux chantés : une grosse part de mes morceaux s'oriente vers une valeur proche de 1 dans l'axe intrumentalness. De même que mes morceaux sont principalement énergiques : il y a une densité plus forte de morceaux dès que l'indice energy se rapproche de 1. Enfin, on voit que danser n'est pas ma préoccupation première : les trois derniers graphes montrent bien que tous les morceaux se répartissent bien sur l'ensemble de l'axe danceability.
Passons maintenant à l'analyse de clusters. Commençons par le plus gros, celui représenté en violet. Ce dernier est très dense dans tous les graphes. Il occupe des coins très spécifiques : beaucoup d'énergie, très peu d'acoustique, principalement dansant et pas mal chanté. On a ici le gros morceau de ma bibliothèque : les chansons aux instrus électroniques pleines d'énergie ! Voilà un morceau issue de ce cluster :
Le cluster suivant est le jaune. Il se rapproche du cluster violet pour la forte présence du chant. En revanche, il diverge quand il s'agit de l'acoustique (il y en a beaucoup) et de l'énergie (il n'y en a bien moins). Ce cluster présente des chansons qui se dansent un peu moins que celles du cluster précédent. On a ici plutôt les chansons calmes, issues de la folk ou indés. On trouve par exemple ce morceau :
Ensuite, on trouve le cluster vert. Celui-ci se confond avec le cluster violet tant qu'on ne parle pas du chant : ses morceaux partagent son énergie, son côté électronique, mais on trouvera en revanche peu de chant. On trouve ce morceau comme bon réprésentant de ce cluster :
Enfin, le dernier cluster, le plus rare, est le bleu. Sans chanson, moins dansant que tous les autres, très acoustique, il est le cluster des morceaux calmes et mélodiques. On y trouve par exemple ce morceau d'Ibrahim Maalouf :
Conclusion
C'est marrant de voir qu'à partir de mesures numériques et d'algorithmes on arrive à « classer » des trucs qui nous semblent en premier lieu assez subjectifs. C'est un peu ça la magie de l'informatique. À partir de mesures numériques, on arrive à créer des catégories à travers lesquelles identifier les grandes familles de musique de notre bibliothèque.
Après, je pense qu'ici nous pouvons relativiser le talent de l'algorithme. Si on regarde nos données de plus près, on se rend compte que les valeurs sont assez polarisées : soit ça chante, soit ça chante pas; soit ça bouge, soit ça bouge pas etc. Finalement, le clustering ici ne donne forme qu'à des séparations qui était assez explicite à l'origine. Mais bon, ça reste quand même intéressant à étudier :)